
As I mentioned in a previous post I’ve recently been looking into the challenges of search log analysis and in particular the prospects for deriving a ‘taxonomy of search sessions’. The idea is that if we can find distinct, repeatable patterns of behaviour in search logs then we can use these to better understand user needs and therefore deliver a more effective user experience.
We’re not the first to attempt this of course – in fact the whole area of search log analysis has an academic literature which extends back at least a couple of decades. And it is quite topical right now, with both ElasticSearch and LucidWorks releasing their own logfile analysis tools (ELK and SiLK respectively). So in this post I’ll be discussing some of the challenges in our own work and sharing some of the initial findings.
So let’s dive in. One of the questions I raised in my last post was:
- What features can be reliably extracted from search sessions within different search logs?
This of course depends on the logs you’re working with, which in our case means a variety of sources, but a good place to start is the AOL search log. This log has a somewhat infamous history, but it is useful as it is relatively large and the records contain a variety of fields that offer a range of data mining possibilities. For example, you could extract features such as the following (the citations indicate other researchers who have successfully exploited them):
- Query length (Stenmark 2008, Wolfram 2007): mean # of terms per query
- Session duration (Chen & Cooper 2001, Stenmark 2008, Weber & Jaimes 2011): Time from first action to session timeout (e.g. 30 mins).
- Number of queries (Chen & Cooper 2001, Stenmark 2008, Wolfram 2007, Weber & Jaimes 2011): any search string entered by the user
- Number of viewed hits / items retrieved (Chen & Cooper 2001, Stenmark 2008, Weber & Jaimes 2011): any link clicked by the user
- Requested result pages (Stenmark 2008): number of explicit page requests
- Number of activities (Stenmark 2008): sum of all the interactions with the system
These features are all reasonably straightforward to extract from the AOL logs using Python or any scripting language of your choice, and the can be output stored as a set of feature vectors for each session. There are of course a great many other features we could extract or derive, and the process of feature selection is something we should consider carefully. But for now I’d like to move onto another question from last week:
- What are the most effective techniques for revealing usage patterns (e.g. unsupervised learning, clustering, etc.)?
At this stage there is no ‘right answer’ in the sense that we don’t know what patterns to expect, so it makes sense to adopt an exploratory strategy and try a few different approaches. We could try clustering them using a data mining tool like Weka, for example. Weka is useful as it provides an extensive range of algorithms for unsupervised learning and a set of helpful (but somewhat less polished) routines for result visualisation.
So if we take a random sample of 100,000 sessions from the AOL log, apply some feature scaling then a clustering algorithm such as Expectation Maximization we get a result like this:
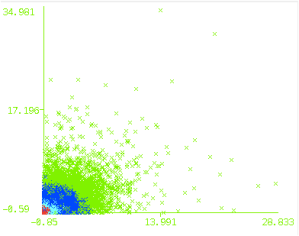
- 100,000 AOL sessions, queries vs. clicks

This reveals 4 clusters, projected into a 2d-space defined by the number of queries & the number of clicks. Note that there is nothing magical about the number 4; if you take a different log or use different features you’ll almost certainly get a different result. So it is important to perform multiple iterations, to ensure that the patterns are stable, i.e. replicable across different samples from the same population.
Let’s focus for a moment on the image above: what does it tell us? Well, not a lot so far: the presence of 4 clusters may be significant but the projection doesn’t deliver much insight into that. Instead, we need something like the following:

- EM using 6 features

This shows how the mean values for the 4 clusters vary across the 6 features. But now it’s the data that is somewhat underwhelming: it suggests that we have a group of users who are relatively highly engaged (i.e. demonstrate a lot of interactions), a group who do relatively little and two other groups in between. Well, duh – this is hardly the kind of stuff that will have customer research professionals fearing for their jobs.
Perhaps the features aren’t ideal? After all we have just 6 so far that were selected on the basis of convenience more than anything. To be maximally useful (e.g. indicative of a latent variable such as ‘behaviour type’), we’d want them to be relatively independent, i.e. uncorrelated with each other. But if we run a Pearson correlation across the ones above we find the opposite: most of them are actually highly correlated, particularly pairs such as ‘all Actions’ and ‘Duration’. Perhaps these redundant features are ‘drowning out’ interesting patterns we might otherwise see? Let’s try dropping ‘All Actions’ and adding in two new features, which are less likely to be correlated with overall engagement levels:
- Term use frequency (Wolfram 2007): average frequency of usage of each query term within the session
- Query interval (Wolfram 2007): average time between query submissions within a session
Now the results seem a bit more interesting:

- EM using 7 features
- Cluster 0 seems to be a relatively small group users who are highly engaged, in long sessions but issuing queries that are diverse / heterogeneous (possibly changing topic repeatedly)
- Cluster 1 seems to be a large group of users who engage in short sessions but often repeat their query terms and do more paging than querying
- Cluster 2 seems to be a middle or ‘general’ group, whose defining characteristics we’ll know more about when we’ve implemented more features (see below).
So obviously from this point there’s a number of different ways we could go. But instead of just adding more features & applying ever more exotic visualisations to new data sources, it might make sense to take a moment to reflect on the process itself and confirm that what we are doing really is valid and repeatable. One way to do this is to replicate other published studies and compare the results. For example, Wolfram’s (2007) paper used the following features:
- Session size – the number of queries submitted for the session
- Terms used per query – the average number of terms used per query over the session
- Term popularity – the average frequency of usage of each query term within the session when
- Term use frequency – the average frequency of usage of each query term within the session
- Query interval – the average time between query submissions within a session
- Pages viewed per query – the average number of page requests per query within a session
He applied these to a number of search logs and showed (among other things) evidence of 4 distinct behavioural patterns in a sample of ~65,000 web search sessions from the Excite 2001 data set. If we can replicate his results, then we not only vindicate the specific conclusions he reached, but more importantly, provide evidence that our approach is valid and scalable to new data sources and research questions.
But this is where things seem to go slightly AWOL. Instead of seeing the 4 clusters that Wolfram saw, we get something like this:

- EM using Wolfram’s 6 features

That’s 3 clusters, not 4. And some very different patterns. Now we could of course rationalise these clusters and make various behavioural inferences concerning them, but the point is that with the possible exception of Cluster 2, they are very different to Wolfram’s. Of course, we are using a different log, and our interpretation of the features may vary from his. But either way I’d hoped to see a bit more consistency than this. Moreover, when we take a further 3 samples from the AOL log, we get a different numbers of clusters (7, 10 and 10)- so the patterns aren’t even replicable within the same population. This happens both for samples sizes of 10,000 and 100,000 sessions (of which the latter take several hours to complete, so this trying out different combinations can take some time).
So something is clearly amiss. It could be a number of things:
- Our interpretation of his description of the features, e.g. does query interval mean the elapsed time between any interaction or is it strictly keyword queries, i.e. no paginations or clicks?
- Our implementation of them, e.g. should term popularity ignore function words? (If not they can easily dilute the meaning-bearing terms in the query)
- our clustering process: at one point Wolfram suggests that in some case he may have set the number of clusters a priori “stable clusters (i.e. replicable) emerge through optimal cluster selection, or specified numbers of clusters”
Or some other factor we have yet to consider.
And on that cliff hanger, I’ll leave you for this week. I’ll follow up with more news as I get it but if you have any insight or suggestions re the above, we’d love to hear it 🙂
References
- Chen, H-M., and Cooper, M.D. (2001). Using clustering techniques to detect usage patterns in a web-based information system. Journal of the American Society for Information Science and Technology, 52(11): 888– 904.
- Jansen, B. J. (2006). Search log analysis: What is it; what’s been done; how to do it. Library and Information Science Research, 28(3): 407–432.
- Stenmark, D. (2008). Identifying clusters of user behavior in intranet search engine log files. Journal of the American Society for Information Science and Technology, 59(14): 2232-2243.
- Wolfram, D., Wang, P., and Zhang, J. (2008). Modeling Web session behavior using cluster analysis: A comparison of three search settings, In Proceedings of the American Society for Information Science and Technology, 44(1): 1550-8390.
- Weber, I., and Jaimes, A. (2011). Who uses web search for what: and how? In Proceedings of the fourth ACM international conference on Web search and data mining (WSDM ’11). ACM, New York, NY, USA, 15-24.